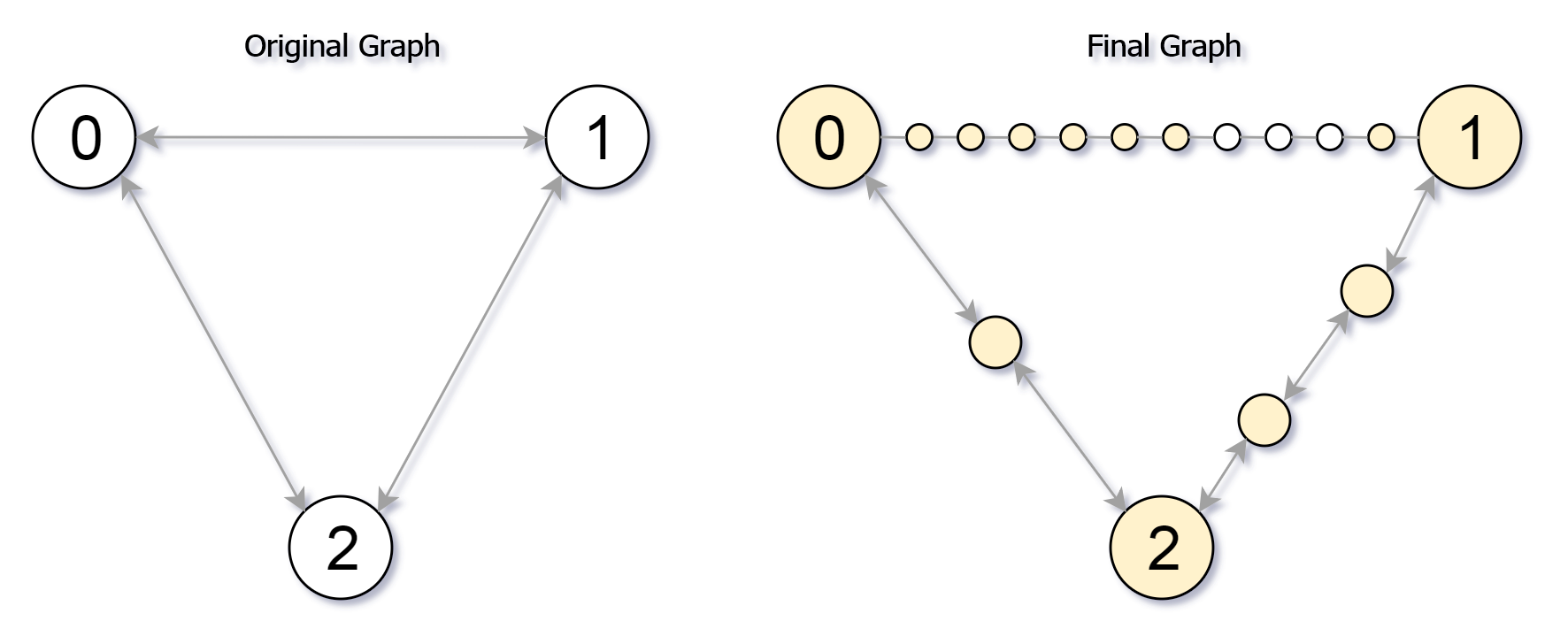
Starting with an undirected graph (the “original graph”) with nodes from 0 to N-1, subdivisions are made to some of the edges.
The graph is given as follows: edges[k] is a list of integer pairs (i, j, n) such that (i, j) is an edge of the original graph,
and n is the total number of new nodes on that edge.
Then, the edge (i, j) is deleted from the original graph, n new nodes (x_1, x_2, ..., x_n) are added to the original graph,
and n+1 new edges (i, x_1), (x_1, x_2), (x_2, x_3), ..., (x_{n-1}, x_n), (x_n, j) are added to the original graph.
Now, you start at node 0 from the original graph, and in each move, you travel along one edge.
Return how many nodes you can reach in at most Mmoves.
Example 1:
Input: `edges` = [[0,1,10],[0,2,1],[1,2,2]], M = 6, N = 3
Output: 13
Explanation:
The nodes that are reachable in the final graph after M = 6 moves are indicated below.
Example 2:
Input: `edges` = [[0,1,4],[1,2,6],[0,2,8],[1,3,1]], M = 10, N = 4
Output: 23
Note:
0 <= edges.length <= 100000 <= edges[i][0] < edges[i][1] < N- There does not exist any
i != jfor whichedges[i][0] == edges[j][0]andedges[i][1] == edges[j][1]. - The original graph has no parallel edges.
0 <= edges[i][2] <= 100000 <= M <= 10^91 <= N <= 3000- A reachable node is a node that can be travelled to using at most M moves starting from node 0.
这道题给了我们一个无向图,里面有N个结点,但是每两个结点中间可能有多个不同的结点,假设每到达下一个相邻的结点需要消耗一步,现在我们有M步可以走,问我们在M步内最多可以到达多少个不同的结点。这里虽然有N个有编号的大结点,中间还有若干个没有编号的小结点,但是最后在统计的时候不分大小结点,全都算不同的结点。为了更好的理解这道题,实际上可以把N个有编号的结点当作N个大城市,比如省会城市,每两个省会城市中间有多个小城市,假设我们每次坐飞机只能飞到相邻的下一个城市,现在我们最多能坐M次飞机,问从省会大城市0出发的话,最多能到达多少个城市。由于省会城市是大型中转站,所以只有在这里才能有多个选择去往不同的城市,而在两个省会城市中的每个小城市,只有前后两种选择,所以这道题实际上还是一种图的遍历,只不过不保证每次都能到有编号的结点,只有到达了有编号的结点,才可以继续遍历下去。当到达了有编号的结点时,还要计算此时的剩余步数,就是用前一个有编号结点的剩余步数,减去当前路径上的所有小结点的个数。假如当前的剩余步数不够到达下一个大结点时,此时我们要想办法标记出来我们走过了多少个小结点,不然下次我们通过另一条路径到达相同的下一个大结点时,再往回走就有可能重复统计小结点的个数。由于小结点并没有标号,没法直接标记,只能通过离最近的大结点的个数来标记,所以虽然这道题是一道无向图的题,但是我们需要将其当作有向图来处理,比如两个大结点A和B,中间有10个小结点,此时在A结点时只有6步能走,那么我们走了中间的6个结点,此时就要标记从B出发往A方向的话只有4个小结点能走了。
再进一步来分析,其实上对于每个结点来说(不论有没有编号),若我们能算出该结点离起始结点的最短距离,且该距离小于等于M的话,那这个结点就一定可以到达。这样来说,其实本质就是求单源点的最短距离,此时就要祭出神器迪杰斯特拉算法 Dijkstra Algorithm 了,LeetCode 中使用了该算法的题目还有 Network Delay Time 和 The Maze II。该算法的一般形式是用一个最小堆来保存到源点的最小距离,这里我们直接统计到源点的最小距离不是很方便,可以使用一个小 trick,即用一个最大堆来统计当前结点所剩的最大步数,因为剩的步数越多,说明距离源点距离越小。由于 Dijkstra 算法是以起点为中心,向外层层扩展,直到扩展到终点为止。根据这特性,用 BFS 来实现时再好不过了,首先来建立邻接链表,这里可以使用一个 NxN 的二维数组 graph,其中 graph[i][j] 表示从大结点i往大结点j方向会经过的小结点个数,建立邻接链表的时候对于每个 edge,要把两个方向都赋值,前面解释过了这里要当作有向图来做。然后使用一个最大堆,里面放剩余步数和结点编号组成的数对儿,把剩余步数放前面就可以默认按步数从大到小排序了,初始化时把 {M,0} 存入最大堆。还需要一个一维数组 visited 来记录某个结点是否访问过。在 while 循环中,首先取出堆顶元素数对儿,分别取出步数 move,和当前结点编号 cur,此时检查若该结点已经访问过了,直接跳过,否则就在 visited 数组中标记为 true。此时结果 res 自增1,因为当前大结点也是新遍历到的,需要累加个数。然后我们需要遍历所有跟 cur 相连的大结点,对于二维数组形式的邻接链表,我们只需要将i从0遍历到N,假如 graph[cur][i] 为 -1,表示结点 cur 和结点i不相连,直接跳过。否则相连的话,两个大结点中小结点的个数为 graph[cur][i],此时要跟当前 cur 结点时剩余步数 move 比较,假如 move 较大,说明可以到达结点i,将此时到达结点i的剩余步数 move-graph[cur][i]-1(最后的减1是到达结点i需要的额外步数)和i一起组成数对儿,加入最大堆中。由于之前的分析,结点 cur 往结点i走过的所有结点,从结点i就不能再往结点 cur 走了,否则就累加了重复结点,所以 graph[i][cur] 要减去 move 和 graph[cur][i] 中的较小值,同时结果 res 要累加该较小值即可,参见代码如下:
解法一:
class Solution {
public:
int reachableNodes(vector<vector<int>>& edges, int M, int N) {
int res = 0;
vector<vector<int>> graph(N, vector<int>(N, -1));
vector<bool> visited(N);
priority_queue<pair<int, int>> pq;
pq.push({M, 0});
for (auto &edge : edges) {
graph[edge[0]][edge[1]] = edge[2];
graph[edge[1]][edge[0]] = edge[2];
}
while (!pq.empty()) {
auto t= pq.top(); pq.pop();
int move = t.first, cur = t.second;
if (visited[cur]) continue;
visited[cur] = true;
++res;
for (int i = 0; i < N; ++i) {
if (graph[cur][i] == -1) continue;
if (move > graph[cur][i] && !visited[i]) {
pq.push({move - graph[cur][i] - 1, i});
}
graph[i][cur] -= min(move, graph[cur][i]);
res += min(move, graph[cur][i]);
}
}
return res;
}
};
我们也可以使用 HashMap 来建立邻接链表,最后的运行速度果然要比二维数组形式的邻接链表要快一些,其他的地方都不变,参见代码如下:
解法二:
class Solution {
public:
int reachableNodes(vector<vector<int>>& edges, int M, int N) {
int res = 0;
unordered_map<int, unordered_map<int, int>> graph;
vector<bool> visited(N);
priority_queue<pair<int, int>> pq;
pq.push({M, 0});
for (auto &edge : edges) {
graph[edge[0]][edge[1]] = edge[2];
graph[edge[1]][edge[0]] = edge[2];
}
while (!pq.empty()) {
auto t= pq.top(); pq.pop();
int move = t.first, cur = t.second;
if (visited[cur]) continue;
visited[cur] = true;
++res;
for (auto &a : graph[cur]) {
if (move > a.second && !visited[a.first]) {
pq.push({move - a.second - 1, a.first});
}
graph[a.first][cur] -= min(move, a.second);
res += min(move, a.second);
}
}
return res;
}
};
Github 同步地址:
https://github.com/grandyang/leetcode/issues/882
参考资料:
https://leetcode.com/problems/reachable-nodes-in-subdivided-graph/
LeetCode All in One 题目讲解汇总(持续更新中…)
转载请注明来源于 Grandyang 的博客 (grandyang.com),欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 grandyang@qq.com




